Accelerating Llm Inference With Speculative Decoding Information Center
Get comprehensive updates, key reports, and detailed insights compiled from verified editorial sources.
About of Accelerating Llm Inference With Speculative Decoding

Ready to become a certified watsonx AI Assistant Engineer? Register now and use code IBMTechYT20 for 20% off of your exam ... THE CLUE MATRIX — one foundational idea, taught deeply, every day. Two AI voices teach a single technical concept from first ... High latency is the primary bottleneck for delivering responsive, user-facing large language model ( Try Voice Writer - speak your thoughts and let AI handle the grammar: This episode of TalkTensors dives into a cutting-edge research paper on This video overview explores the mechanics and production performance of
Open-source LLMs are great for conversational applications, but they can be difficult to scale in production and deliver latency ... Abstract: We will discuss how vLLM combines continuous batching with About the seminar: Speaker: Ion Stoica (Berkeley & Anyscale & Databricks) Title: About the seminar: Speaker: Hongyang Zhang (Waterloo & Vector Institute) Title: EAGLE and ...
Main Features

Explore the key sources for Accelerating Llm Inference With Speculative Decoding.
Latest News

Stay updated on Accelerating Llm Inference With Speculative Decoding's latest milestones.
Featured Video Reports & Highlights
Below is a handpicked selection of video coverage, expert reports, and highlights regarding Accelerating Llm Inference With Speculative Decoding from verified contributors.

Faster LLMs: Accelerate Inference with Speculative Decoding

Accelerating LLM Inference with Speculative Decoding
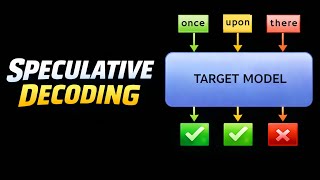
Speculative Decoding: 3× Faster LLM Inference with Zero Quality Loss

Lossless LLM inference acceleration with Speculators
Deep Dive
Data is compiled from public records and verified media reports.
Last Updated: May 26, 2026
Final Thoughts

For 2026, Accelerating Llm Inference With Speculative Decoding remains one of the most talked-about profiles. Check back for the latest updates.
Disclaimer:



















